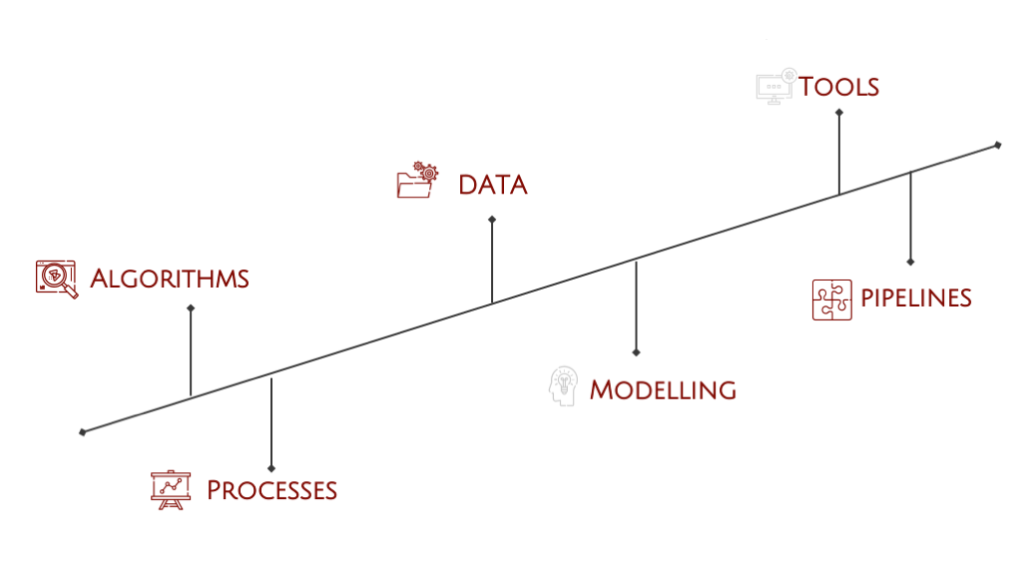
O prezentare a contexului Data Science – roluri, algoritmi, instrumente, pipelines și procese, toate rezumate într-o imagine de ansamblu.
Ce este Data Science?
- Data science nu este un domeniu propriu-zis, ci o unificare a statisticii, modelelor analitice și informaticii.
- Un Data scientist înțelege datele pentru a oferi valoare adăugată pentru un anumit scenariu prestabilit.
- Este obișnuit ca Data scientist-ii să lucreze îndeaproape cu oamenii de business. Rolul Data Scientist-ului este de a înțelege nevoia și de a o transpune într-o soluție de Data Science.
- Data Science nu este un domeniu de programare obișnuit (de exemplu, Dezvoltarea unei aplicații mobile), ci mai degrabă se îndreaptă spre cercetare și dezvoltare sau încercări și erori.
Datele
- Un data scientist se ocupă de obicei cu două categorii principale de date care sunt:
- Structurate (de exemplu: tabele, jsons, csvs etc.) și
- Nestructurate (text, imagini, videoclipuri etc.)
- Înainte de a aplica orice algoritm, un lucru important de ținut cont reprezintă etichetarea datelor. Etichetarea se referă la atribuirea unei valori semantice unei date (de exemplu, o imagine a unei pisici, un text științific etc.)
- Pentru majoritatea algoritmilor, datele trebuie să fie organizate pe scară largă în puncte de date cu o etichetă sau nu. Acestea trebuie să fie omogene în ceea ce privește faptul că au aceleași „caracteristici” pentru datele structurate sau sunt de un anumit tip pentru datele nestructurate (de exemplu, date tranzacționale pentru imagini structurate și numai imagini care nu sunt amestecate cu puncte de date text pentru nestructurate).
Algoritmii
- Algoritmii pentru data science se împart în două categorii principale: învățare supravegheată și nesupravegheată. Învățarea supravegheată înseamnă încercarea de a „învăța” o anumită etichetă adnotată umană, iar învățarea nesupravegheată „învață” de asemenea, dar nu spre un „adevăr fundamental” dat, alias eticheta.
- Pentru a simplifica excesiv, toți algoritmii reprezintă modele statistice avansate, numite „învățare automată”.
- Ele se diversifică în continuare în regresie și clasificare pentru învățarea supravegheată și în gruparea / detecția anomaliilor pentru învățarea nesupravegheată.
- Unii algoritmi notați sunt SVM/Decision Tree pentru învățarea automată „clasică”, precum și rețelele neuronale pentru învățare profundă nouă, care au o multitudine de variații fiind un domeniu propriu.
Procesele
- Această secțiune se referă la metodele care sunt aplicate după stabilirea datelor pentru dezvoltarea unui model. Datele din viața reală sunt de obicei dezordonate și trebuie procesate în continuare pentru a fi utilizabile.
- Astfel de procese constau în imputare – care se ocupă cu valorile lipsă, netezirea, care reprezintă de cele mai multe ori transformarea datelor atunci când sunt prea variate, curățarea care se ocupă cu modificarea diferitelor caracteristici (de exemplu, ștergerea coloanelor nesemnificative din datele tabelare, repararea literelor mari/mici în text, împărțirea unei coloane în două etc).
- Un alt proces important este generarea de caracteristici (de exemplu, agregarea datelor, TFIDF, PCA, ONE-HOT-ENCODING etc).
Modelarea
- Modelarea este activitatea de bază a data scientis-ului și a „produsului final”. Pentru a modela ceva, mai mulți algoritmi sunt rulați pe sistemul „probă” pentru „învățare”.
- De obicei, acest lucru nu este simplu și sunt necesare mai multe iterații, precum și revenirea la pașii anteriori.
- Pe scurt, un model este o „cutie neagră” care este capabilă să generalizeze un anumit subiect și să ofere un rezultat probabil și calitativ ridicat (de exemplu, ce imagini sunt probabil pisici, este un client care va scăpa de afacere, nu este această persoană ca celelalte etc).
Pipelines
- În afară de diferitele procese care pot apărea cu anumite probleme specicie, procesul de data science are un șir de pipeline-uri care pot fi generalizate.
- ETL înseamnă Extract, Transform, Load și este etapa de achiziție a datelor care reunește toate datele din eventuale surse multiple.
- EDA înseamnă Exploratory Data Analysis și obține o introspecție vizuală în date (de exemplu, grafice, statistici, dependențe etc.).
- DQ înseamnă calitatea datelor și scopul este de a remedia/elimina/evaluează calitatea datelor pe care le-a primit cercetătorul de date.
- Servirea și implementarea sunt de obicei realizate de echipa MLOps, însă de cele mai multe ori în colaborare strânsă cu data scientist-ul.
Instrumente
- În ceea ce privește instrumentele, există o mare piață open-source, însă totuși există unele tool-uri recomandate, care au cele mai mari comunități ce le susțin.
- Baza Data Science este limbajul de programare Python.
- Pentru algoritmi, există tensorflow pentru deep learning și sklearn pentru multe altele.
- Pandas și SQL sunt obligatorii pentru ETL.
- Plotly/Matplotlib sunt biblioteci grafice foarte interesant pentru EDA.
- Spark/Hadoop/Kafka sunt soluții pentru gestionarea unor cantități mari de date și streaming, precum și ETL.
- Airflow este cea mai bună soluție din clasă pentru orchestrarea/implementarea/servirea/automatizarea modelelor pregătite pentru producție.